
들어가며
앞서 숙소 예약 서비스를 개발하며 숙소 검색 API의 응답 속도가 3초 대의 느린 성능을 확인하여, 최적화를 위해 문제를 분석하던 중 N+1 문제가 발생해 이를 62개의 쿼리 3개로 줄이며 N+1 문제를 해결했습니다.
[JPA] N+1 문제 해결: 62개의 쿼리를 3개의 쿼리로
들어가며숙소 예약 서비스를 개발하던 중 가장 많이 호출되는 숙소 검색 API의 응답속도가 느리다는 것을 파악하고, 쿼리를 개선하는 것을 목표로 작업을 하게 되면서 만나게 된 N + 1 문제의 해
mudhub.tistory.com
N+1 문제를 해결했음에도, 여전히 숙소 검색 API의 응답속도는 크게 변화되지 않았고 오히려 더 많은 실행 시간이 발생했습니다. 그래서 다시 한번 숙소 검색 API의 속도를 개선하고자, 발생하는 3가지의 쿼리를 살펴보기로 했습니다.
Query Execution Plan
현재 사용하고 있는 데이터 베이스인, MySQL의 경우 내부적으로 Optimizer(옵티마이저)를 통해 쿼리를 어떻게 실행할지 결정합니다.
Optimizer는 다음과 같은 역할을 합니다.
- 테이블 스캔을 방법 선택
- 인덱스 선택
- 조인 순서 결정
- 서브쿼리 최적화
Optimizer는 이름 그대로, 사용자가 실행한 쿼리를 데이터베이스의 여러 상황을 고려해 가장 효율적인 경로로 처리하도록 최적화합니다. 이때 옵티마이저가 수립하는 처리 절차를 Query Execution Plan(쿼리 실행 계획)이라고 합니다.
Query Execution Plan 확인
쿼리가 어떤 인덱스를 사용하고 어떻게 테이블을 스캔할지는 Optimizer가 결정하므로 개발자가 직접 제어할 수는 없습니다. 하지만 풀 테이블 스캔이 발생할 때 적절한 인덱스를 추가해 주면, 옵티마이저가 해당 인덱스를 사용하도록 유도하여 성능을 개선하는 것은 가능합니다.
그래서 MySQL은 사용자가 이 내부 동작을 확인할 수 있도록 다음과 같은 기능들을 제공합니다.
EXPLAIN
먼저 EXPLAIN입니다. 사용법은 간단한데, 실행할 쿼리 앞에 EXPLAIN만 붙여주면 됩니다.(SELECT, INSERT, UPDATE, DELETE, REPLACE, TABLE 쿼리에 사용 가능)
mysql> EXPLAIN SELECT Name FROM country WHERE Code Like 'A%';
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | country | NULL | range | PRIMARY | PRIMARY | 12 | NULL | 17 | 100.00 | Using where |
+----+-------------+---------+------------+-------+---------------+---------+---------+------+------+----------+-------------+실행하게 되면 다음과 같이 표 형식의 결과물이 나옵니다.(기본적인 출력형식은 TRADITIONA이며, TREE 형식, JSON 형식으로도 출력가능)
다음과 나온 결과는 해당 쿼리를 내부적으로 Optimizer가 어떻게 실행할 것인지, 예상 결과를 보여줍니다. 중요한 점은, 이 과정에서 실제 쿼리가 실행되지는 않는다는 것입니다. 따라서 아무리 무거운 쿼리라도 EXPLAIN을 통해 실행 계획을 확인하는 것은 시스템에 부하를 주지 않고 빠르고 안전하게 확인할 수 있습니다.
MySQL :: MySQL 8.0 Reference Manual :: 10.8.2 EXPLAIN Output Format
10.8.2 EXPLAIN Output Format The EXPLAIN statement provides information about how MySQL executes statements. EXPLAIN works with SELECT, DELETE, INSERT, REPLACE, and UPDATE statements. EXPLAIN returns a row of information for each table used in the SELECT
dev.mysql.com
각 컬럼마다 어떤 의미를 갖고, 어떤 속성을 갖고 있는지에 대한 자세한 내용은 MySQL 공식문서를 참고하면 좋을 거 같습니다.
EXPLAIN ANALYZE
MySQL은 8.0.18 버전부터 EXPLAIN 보다 추가적인 정보를 제공하여 보다 더 정확한 쿼리 최적화를 할 수 있도록 EXPLAIN ANALYZE를 제공합니다.
EXPLAIN ANAYLYZE도 EXPLAIN과 같이 동일하게 실행할 쿼리 앞에 'EXPLAIN ANALYZE' 붙여 실행만 해주면 됩니다.(SELECT, UPDATE, DELETE, TABLE에 사용 가능)
하지만 둘의 차이점은 EXPLAIN의 경우 쿼리 내부적인 쿼리를 실행하지 않고 예상 결과를 보여주는 반면, EXPLAIN ANALYZE는 실제로 쿼리를 실행하여, 옵티마이저의 예상(cost, rows)과 실제 실행 결과(actual time, rows)를 비교할 수 있게 해 준다는 결정적인 차이가 있습니다. 이를 통해 옵티마이저의 예측이 얼마나 정확했는지, 어느 단계에서 예상보다 많은 시간과 비용이 소요되었는지를 명확히 파악할 수 있습니다.
단, 쿼리를 실제로 실행하기 때문에 INSERT, UPDATE, DELETE 같은 DML 쿼리에 사용할 경우 데이터 변경이 실제로 발생하며, 실행 시간이 긴 쿼리는 시스템에 부하를 줄 수 있으므로 주의해야 합니다.
실행하게 되면 다음과 같은 TREE 형태로 실행 결과를 보여줍니다.
mysql> EXPLAIN ANALYZE SELECT * FROM t1 JOIN t2 ON (t1.c1 = t2.c2)\G
*************************** 1. row ***************************
EXPLAIN: -> Inner hash join (t2.c2 = t1.c1) (cost=4.70 rows=6) (actual time=0.032..0.035 rows=6 loops=1)
-> Table scan on t2 (cost=0.06 rows=6) (actual time=0.003..0.005 rows=6 loops=1)
-> Hash
-> Table scan on t1 (cost=0.85 rows=6)(actual time=0.018..0.022 rows=6 loops=1)실제로 내부적으로 실행되는 순서는 출력 결과에서 가장 안쪽 들여 쓰기(depth)가 깊은 부분부터입니다. 그리고 속성마다 다양한 정보들을 제공해 줍니다.
- cost: Optimizer가 예상한 작업 비용으로 절대적인 시간이 아닌, 다른 작업과의 상대적인 비용 크기를 비교하는 데 사용
- actual time: 해당 작업을 실제로 실행했을 때 소요된 시간 (ms 단위)으로 (실제 시작 시간.. 실제 종료 시간) 형태로 표시.
- rows: Optimizer가 예상한 결과 행 수
- (actual) rows: 실제로 반환된 행 수
- loops: 해당 작업이 반복 실행된 횟수
숙소 검색 API 쿼리 실행 계획 확인
그럼 앞서 말한 두 가지 기능 중 보다 더 정확한 최적화를 위해 EXPLAIN ANALIZE를 통해 내부동작을 확인 후 최적화를 진행해 봤습니다.
숙소 검색 API의 실행되는 쿼리는 다음과 같습니다.
- 숙소를 조회하는 쿼리
- 숙소 개수를 조회하는 쿼리
- 숙소 옵션 정보를 조회하는 쿼리
3개의 쿼리의 각각 내부적으로 어떻게 동작하고 있는지 확인해 봤습니다.
첫 번째 쿼리
EXPLAIN ANALYZE
SELECT
a1_0.id,
a1_0.address_id,
a2_0.id AS address_id,
a2_0.base_address,
a2_0.country,
a2_0.detailed_address,
a2_0.location,
a1_0.bathroom_count,
a1_0.bed_count,
a1_0.bedroom_count,
a1_0.created_at,
a1_0.currency,
a1_0.description,
a1_0.max_guests,
a1_0.name,
a1_0.price_per_day,
a1_0.updated_at
FROM
accommodation a1_0
JOIN
address a2_0
ON a2_0.id = a1_0.address_id
WHERE
a1_0.price_per_day >= 100000
AND a1_0.price_per_day <= 500000
AND a1_0.max_guests >= 1
AND NOT EXISTS (
SELECT 1
FROM availability a3_0
WHERE a3_0.accommodation_id = a1_0.id
AND a3_0.date IN ('2025-08-28', '2025-08-30')
)
AND ST_Distance_Sphere(
a2_0.location,
ST_SRID(POINT(126.9780, 37.5665), 4326)
) <= 5000
ORDER BY
a1_0.price_per_day
LIMIT 0, 30;-> Limit: 30 row(s) (cost=1.17e+6 rows=30) (actual time=1092..1982 rows=30 loops=1)
-> Nested loop antijoin (cost=1.17e+6 rows=9e+6) (actual time=1092..1982 rows=30 loops=1)
-> Nested loop inner join (cost=236223 rows=987610) (actual time=1092..1982 rows=30 loops=1)
-> Sort: a1_0.price_per_day (cost=110632 rows=987610) (actual time=1078..1112 rows=152335 loops=1)
-> Filter: ((a1_0.price_per_day >= 100000) and (a1_0.price_per_day <= 500000) and (a1_0.max_guests >= 1)) (cost=110632 rows=987610) (actual time=0.0726..614 rows=635469 loops=1)
-> Table scan on a1_0 (cost=110632 rows=987610) (actual time=0.0709..551 rows=1e+6 loops=1)
-> Filter: (st_distance_sphere(a2_0.location,<cache>(st_srid(point(126.9780,37.5665),4326))) <= 5000) (cost=0.734 rows=1) (actual time=0.00565..0.00565 rows=197e-6 loops=152335)
-> Single-row index lookup on a2_0 using PRIMARY (id = a1_0.address_id) (cost=0.734 rows=1) (actual time=0.00343..0.00345 rows=1 loops=152335)
-> Filter: (a3_0.`date` in ('2025-08-28','2025-08-30')) (cost=9.26 rows=9.11) (actual time=0.0243..0.0243 rows=0 loops=30)
-> Covering index lookup on a3_0 using UKchn2is0hq8qldeice3wbpyhg1 (accommodation_id = a1_0.id) (cost=9.26 rows=9.11) (actual time=0.0228..0.0236 rows=3.77 loops=30)두 번째 쿼리
EXPLAIN ANALYZE
SELECT
COUNT(a1_0.id)
FROM
accommodation a1_0
JOIN
address a4_0
ON a4_0.id = a1_0.address_id
WHERE
a1_0.price_per_day >= 100000
AND a1_0.price_per_day <= 500000
AND a1_0.max_guests >= 1
AND NOT EXISTS (
SELECT 1
FROM availability a2_0
WHERE a2_0.accommodation_id = a1_0.id
AND a2_0.date IN ('2025-08-28', '2025-08-30')
)
AND ST_Distance_Sphere(
a4_0.location,
ST_SRID(POINT(126.9780, 37.5665), 4326)
) <= 5000;-> Aggregate: count(a1_0.id) (cost=277793 rows=1) (actual time=2235..2235 rows=1 loops=1)
-> Nested loop antijoin (cost=201038 rows=333114) (actual time=4.97..2235 rows=138 loops=1)
-> Nested loop inner join (cost=130525 rows=36567) (actual time=4.27..2230 rows=138 loops=1)
-> Filter: ((a1_0.price_per_day >= 100000) and (a1_0.price_per_day <= 500000) and (a1_0.max_guests >= 1)) (cost=111210 rows=36567) (actual time=0.114..312 rows=635469 loops=1)
-> Table scan on a1_0 (cost=111210 rows=987610) (actual time=0.113..248 rows=1e+6 loops=1)
-> Filter: (st_distance_sphere(a4_0.location,<cache>(st_srid(point(126.9780,37.5665),4326))) <= 5000) (cost=0.428 rows=1) (actual time=0.00296..0.00296 rows=217e-6 loops=635469)
-> Single-row index lookup on a4_0 using PRIMARY (id = a1_0.address_id) (cost=0.428 rows=1) (actual time=824e-6..842e-6 rows=1 loops=635469)
-> Filter: (a2_0.`date` in ('2025-08-28','2025-08-30')) (cost=9.27 rows=9.11) (actual time=0.0337..0.0337 rows=0 loops=138)
-> Covering index lookup on a2_0 using UKchn2is0hq8qldeice3wbpyhg1 (accommodation_id = a1_0.id) (cost=9.27 rows=9.11) (actual time=0.0325..0.033 rows=3.81 loops=138)세 번째 쿼리
EXPLAIN ANALYZE
SELECT
l1_0.accommodation_id,
l1_1.id AS label_id,
l1_1.name AS label_name
FROM
accommodation_label l1_0
JOIN
label l1_1
ON l1_1.id = l1_0.label_id
WHERE
l1_0.accommodation_id IN (
4399, 934817, 784305, 106569, 583077, 286932, 983237, 282482, 251171,
746635, 60996, 699832, 456513, 698740, 579354, 674807, 615123, 800972,
352178, 935329, 87017, 711005, 325384, 341966, 522826, 11786, 492547,
492383, 348196, 635737
);-> Nested loop inner join (cost=1.45 rows=1) (actual time=0.026..0.026 rows=0 loops=1)
-> Filter: (l1_0.accommodation_id in (4399,934817,784305,106569,583077,286932,983237,282482,251171,746635,60996,699832,456513,698740,579354,674807,615123,800972,352178,935329,87017,711005,325384,341966,522826,11786,492547,492383,348196,635737)) (cost=0.35 rows=1) (actual time=0.0255..0.0255 rows=0 loops=1)
-> Table scan on l1_0 (cost=0.35 rows=1) (actual time=0.0227..0.024 rows=1 loops=1)
-> Filter: (l1_1.id = l1_0.label_id) (cost=1.1 rows=1) (never executed)
-> Single-row index lookup on l1_1 using PRIMARY (id = l1_0.label_id) (cost=1.1 rows=1) (never executed)- 첫 번째 쿼리 : 1982ms
- 두 번째 쿼리 : 2235ms
- 세 번째 쿼리 : 0.026ms
숙소 검색 API를 통해 실행되는 세 가지 쿼리의 실행 시간을 측정한 결과, 총 약 4.2초가 소요되는 것을 확인했습니다.
이 중 세 번째 쿼리는 실행 시간이 0.026ms로 매우 짧아 성능에 큰 영향을 주지 않습니다.
문제는 첫 번째 쿼리(숙소 조회 쿼리)와 두 번째 쿼리(숙소 COUNT 쿼리)로, 각각 1982ms와 2235ms가 소요되어 전체 응답 시간을 지연시키고 있었습니다.
참고로, 두 쿼리는 모두 동일한 조건으로 accommodation 테이블을 조회하지만, 첫 번째 쿼리는 조건에 맞는 숙소 중 상위 30개만 조회하는 반면, 두 번째 쿼리는 조건에 맞는 숙소의 전체 개수를 계산하는 COUNT 쿼리입니다. 따라서 두 쿼리는 전반적으로 매우 유사한 형태를 띠고 있습니다.
실행되는 쿼리에 대해서
실행되는 쿼리에 대한 이해를 돕기 위해 관련 테이블에 대해서 설명해 보겠습니다.

숙소 검색 API와 관련된 테이블은 위와 같고, 현재 주목해야 하는 테이블들은 다음과 같습니다.
- accommodation: 숙소 정보 테이블
- address: 숙소 주소 테이블(POINT 데이터 형태로 숙소의 위치정보를 저장)
- reservation: 예약 정보 테이블 (체크인/아웃, 예약자, 숙박 인원 등등 전반적인 예약 정보 저장)
- availability: 숙소 예약 가능 여부 확인 테이블(예약하려는 날짜에 해당 숙소가 예약이 있는지를 확인)
그리고 숙소 검색 API의 요청 시 사용되는 JSON 폼입니다.
{
"longitude": 126.9780, //경도
"latitude": 37.5665, //위도
"minPrice": 100000, //최소 숙박비
"maxPrice": 500000, //최대 숙박비
"maxGuests": 1, //숙박 인원
"checkIn": "2025-08-28", //체크인 날짜
"checkOut": "2025-08-30", //체크아웃 날짜
"page": 1,
"pageSize": 30
}관련 테이블과 위에 JSON 폼으로 숙소 API를 요청했을 때는 다음과 같이 데이터를 가져옵니다.
먼저 accommodation 테이블에서 숙박비와 숙박 인원 조건에 맞는 숙소를 거릅니다. 그다음, 이 숙소들 중 availability 테이블을 참조해 지정한 날짜에 예약이 없는 숙소만 남깁니다. 마지막으로 address 테이블을 조인하여, 지정한 지점으로부터 반경 5km 이내에 위치한 숙소를 최종적으로 찾아냅니다. 이 결과를 첫 번째 쿼리는 가장 저렴한 가격 순으로 정렬하여 상위 30개만 보여주고, 두 번째 쿼리는 결과 모든 개수를 반환합니다.
테스트는 숙소 100만 건과 예약 370만 건의 더미 데이터가 저장되어 있는 환경에서 진행했으며, 검색 조건은 더미 데이터 중 숙소가 가장 많이 분포한 지역과 가격대를 기준으로 설정했습니다.
실행 계획 분석 및 최적화 계획
다시 돌아와 두 쿼리의 Query Execution Plan을 분석해 보겠습니다.
현재 두 쿼리의 Query Execution Plan을 살펴봤을 때, 공통적으로 눈에 띄는 두 가지 부분이 있었습니다.
- Table Full Scan
- 거리 계산 함수(St_Distance_Sphere)
Table Full Scan
첫 번째 쿼리
-> Filter: ((a1_0.price_per_day >= 100000) and (a1_0.price_per_day <= 500000) and (a1_0.max_guests >= 1)) (cost=110632 rows=987610) (actual time=0.0726..614 rows=635469 loops=1)
-> Table scan on a1_0 (cost=110632 rows=987610) (actual time=0.0709..551 rows=1e+6 loops=1)두 번째 쿼리
-> Filter: ((a1_0.price_per_day >= 100000) and (a1_0.price_per_day <= 500000) and (a1_0.max_guests >= 1)) (cost=111210 rows=36567) (actual time=0.114..312 rows=635469 loops=1)
-> Table scan on a1_0 (cost=111210 rows=987610) (actual time=0.113..248 rows=1e+6 loops=1)EXPLAIN ANALYZE 결과를 통해 두 쿼리 모두 Table Full Scan 방식으로 동작하는 것을 확인했습니다.
Table Full Scan은 인덱스를 사용하지 않고 테이블의 모든 데이터를 처음부터 끝까지 훑는 방식입니다. 지금은 약 100만 건의 데이터를 일일이 확인하고 있어 매우 비효율적입니다.
물론 현재는 필터링 결과가 100만 건 중 63만 건으로 매우 많아 응답 속도가 치명적이지는 않습니다. 하지만 검색 결과가 매우 적은 특정 조건에서는 오히려 성능이 급격히 저하될 것이므로 인덱스 추가가 필요하다고 판단했습니다.
인덱스를 필요하다고 판단했지만 추가하기 전, 몇 가지 더 고려해야 할 상황들이 있었습니다.
- 읽기 vs 쓰기 비용
- 단일 인덱스 vs 복합 인덱스
읽기 vs 쓰기 비용
인덱스는 조회 시 적은 비용으로 빠른 검색을 가능하게 하지만, 반대로 데이터 추가나 수정 시에는 인덱스를 갱신해야 하므로 쓰기 비용이 증가합니다.
따라서 accommodation 테이블에 데이터가 얼마나 자주 추가되거나 수정되는지를 우선 고려했습니다.
일반적으로 숙소 예약 플랫폼에서는 예약 데이터가 자주 추가되지만, 숙소 정보 자체가 등록되거나 수정되는 빈도는 상대적으로 낮습니다.
반면 숙소 조회 요청은 훨씬 빈번하게 발생하므로, 인덱스를 추가하는 것이 전체적인 성능 향상에 더 유리하다고 판단했습니다.
단일 인덱스 vs 복합 인덱스
인덱스를 추가하기로 결정했으니, 이제 단일 인덱스로 할지 복합 인덱스로 할지를 고민했습니다.
현재 price_per_day와 max_guests는 필수 검색 조건이 아닙니다. 즉, 두 조건이 동시에 들어올 수도 있고, 둘 중 하나만 들어오거나, 아예 둘 다 없는 경우도 있을 수 있습니다.
복합 인덱스를 사용할 경우 두 조건이 모두 들어왔을 때는 높은 성능을 기대할 수 있지만, 한 가지 조건만 들어오는 경우에는 인덱스를 타지 않을 가능성이 있습니다.
그 이유는 바로 왼쪽 접두사(Left-Prefix) 규칙 때문입니다. 이 규칙은 “복합 인덱스는 왼쪽부터 순서대로 사용할 때만 효율적으로 적용된다”는 원리입니다.
CREATE INDEX idx_accommodation_price_guests
ON accommodation(price_per_day, max_guests);
즉, 위와 같이 인덱스를 생성한 경우 다음 쿼리는 인덱스를 사용합니다.
WHERE price_per_day = 100000하지만 왼쪽 컬럼(price_per_day)을 사용하지 않고 오른쪽 컬럼만 사용하는 경우, Optimizer는 인덱스를 사용하지 않습니다.
WHERE max_guests = 5
그 이유는 데이터베이스가 인덱스를 구현할 때 사용하는 B-Tree 자료 구조의 근본적인 특징 때문입니다.
B-Tree 인덱스는 데이터를 정렬된 트리 형태로 저장하는데, (A, B) 순서의 복합 인덱스는 다음과 같은 방식으로 정렬됩니다.
- 먼저 A 컬럼을 기준으로 전체 데이터를 정렬합니다.
- A 값이 같은 데이터들끼리 모아서, 그 안에서 다시 B 컬럼을 기준으로 정렬합니다.
따라서 A 값을 모르면 B 값만으로는 정렬된 위치를 찾아갈 수 없게 됩니다.
이 문제를 해결하기 위해 (price_per_day, max_guests)와 (max_guests, price_per_day) 두 개의 복합 인덱스를 만들 수도 있습니다.
하지만 이렇게 하면 쓰기 비용과 저장 공간 사용량이 크게 증가합니다.
이에 비해 단일 인덱스를 사용하는 경우, 복합 인덱스를 두 개 생성하는 것보다 쓰기 비용과 저장 공간 측면에서 효율적이며, MySQL Optimizer가 내부적으로 지원하는 ‘인덱스 병합(Index Merge)’ 기능 덕분에 두 조건이 모두 들어왔을 때도 비교적 좋은 성능으로 조회가 가능합니다.
따라서 각 컬럼에 단일 인덱스를 추가하기로 결정했습니다.
CREATE INDEX idx_accommodation_price ON accommodation(price_per_day);
CREATE INDEX idx_accommodation_guests ON accommodation(max_guests);거리 계산 함수
첫 번째 쿼리
-> Filter: (st_distance_sphere(a2_0.location,<cache>(st_srid(point(126.9780,37.5665),4326))) <= 5000) (cost=0.734 rows=1) (actual time=0.00565..0.00565 rows=197e-6 loops=152335)
-> Single-row index lookup on a2_0 using PRIMARY (id = a1_0.address_id) (cost=0.734 rows=1) (actual time=0.00343..0.00345 rows=1 loops=152335)두 번째 쿼리
-> Filter: (st_distance_sphere(a4_0.location,<cache>(st_srid(point(126.9780,37.5665),4326))) <= 5000) (cost=0.428 rows=1) (actual time=0.00296..0.00296 rows=217e-6 loops=635469)
-> Single-row index lookup on a4_0 using PRIMARY (id = a1_0.address_id) (cost=0.428 rows=1) (actual time=824e-6..842e-6 rows=1 loops=635469)위 결과에서 확인할 수 있듯이, ST_Distance_Sphere 공간 함수를 사용해 거리를 계산하는 구간에서 상당한 비용이 발생하고 있었습니다.
두 번째 쿼리의 경우, 약 63만 개의 데이터에 대해 거리 계산을 수행하면서 1.8초의 실행 시간이 소요되었고, 이는 총 실행 시간 2.2초 중 대부분을 차지하는 구간이었습니다.
숙소 검색 API는 설계상, 특정 지점을 기준으로 반경 5km 내에 존재하는 숙소를 사용자에게 제공해야 하므로, 해당 거리 계산 함수는 필수적인 연산이었습니다.
이에 따라 MySQL 공식 문서와 관련 서적을 참고하며 최적화 방안을 탐색했고, 그 결과 공간 인덱스를 활용해 대략적인 후보군을 먼저 좁히는 방법을 적용하기로 결정했습니다.
제가 생각한 방법은 다음과 같습니다.
- 기준점의 5km Bounding Box(사각형 영역)를 만듭니다.
- 우선 MBRContains 함수를 통해 Bounding Box에 들어오는 숙소 후보를 걸러냅니다.
- ST_Distance_Sphere 공간 함수를 통해 정확히 5km 반경에 들어오는 숙소를 찾습니다.

기존 방식은 ST_Distance_Sphere 함수를 사용해 지정한 지점을 중심으로 반경 5km 이내의 숙소를 원 형태로 정확하게 탐색하는 방식이었습니다.
하지만 앞서 언급했듯이, 해당 함수는 거리 계산 자체에 높은 연산 비용이 발생하며, 이 방식은 공간 인덱스를 활용할 수 없습니다.
그 이유는 공간 인덱스의 저장 방식을 이해하면 명확해집니다.
MySQL(InnoDB 기준으로)은 데이터베이스에 저장된 모든 공간 데이터를 감싸는 최소 경계 사각형(MBR, Minimum Bouding Rectangle) 정보를 공간인덱스로 저장합니다.
예를 들어, 다음과 같은 공간 데이터가 존재한다고 가정해 보겠습니다.
공간 데이터를 공간 인덱스 형태로 저장하게 된다면 다음과 같은 구조로 저장하게 됩니다.

위에 그림은 공간 데이터를 MBR로 둘러싼 모습입니다. 공간 인덱스 생성하게 되면 MBR 정보들을 그룹화하여 계층적으로 저장하게 됩니다.
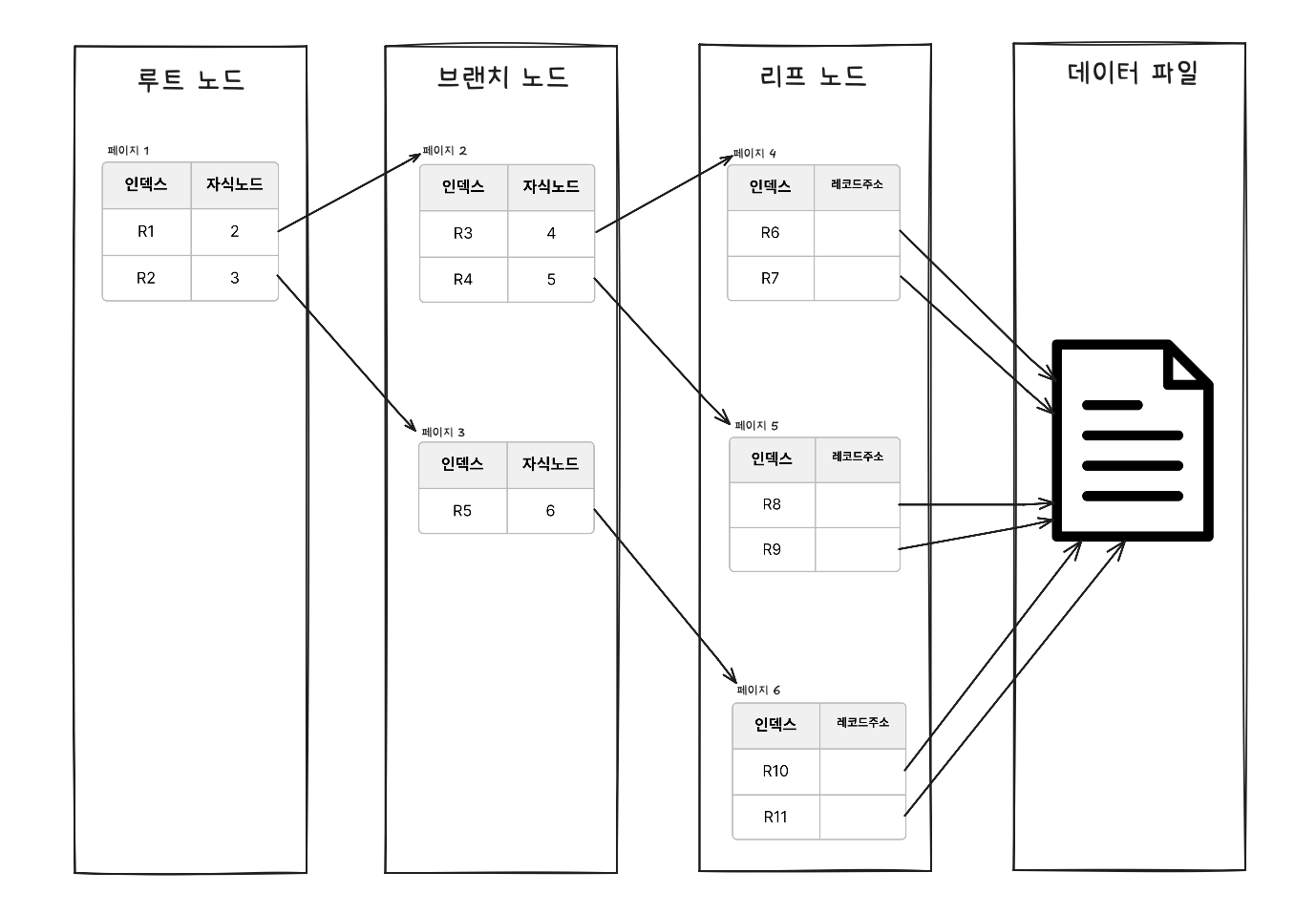
공간 인덱스는 R-Tree 구조를 기반으로, MBR정보를 기준으로 공간 데이터를 저장합니다.
이 구조를 사용하면 공간 데이터를 사각형(Rectangle) 형태로 계층적으로 관리하기 때문에, 데이터 조회 시 겹치는 사각형 영역만 빠르게 탐색하여 검색 속도를 크게 향상시킬 수 있습니다. (참고로 R-Tree의 ‘R’은 Rectangle을 의미합니다.)
반면, ST_Distance_Sphere 함수는 두 지점의 위도와 경도를 입력받아, 지구의 곡률을 고려한 실제 거리(호의 길이)를 계산합니다.
즉, 원형(반경) 기반의 거리 계산을 수행하기 때문에, 사각형 형태로 저장된 공간 인덱스(MBR)와는 구조적으로 맞지 않아 인덱스를 활용할 수 없습니다.
결국 이 함수는 모든 데이터를 직접 계산해야 하므로 성능 저하가 발생하게 됩니다.
이러한 이유로, 빠른 조회를 가능하게 하는 공간 인덱스를 활용하기 위해 MBR 계열 함수 중 MBRContains 함수를 선택했습니다.
MBRContains는 한 도형의 MBR이 다른 도형의 MBR 안에 완전히 포함되는지를 검사하는 함수로, 정확한 거리 계산 대신 사각형 단위의 포함 여부만 판단하기 때문에 매우 빠르게 동작합니다.
MBRContains(a, b)

그래서 저는 사용자가 입력한 기준점으로부터 5km 떨어진 최소·최대 위도와 경도를 계산해, 이를 기반으로 사각형 영역(Bounding Box)을 만들었습니다. 그리고 이 영역 안에 포함되는 숙소들을 공간 인덱스를 이용해 1차적으로 필터링하려고 했습니다.
이렇게 하면 공간 인덱스를 활용해 100만 개의 숙소 중 5km 반경 근처에 있는 숙소 후보를 빠르게 추출할 수 있습니다.
그 후, 이렇게 걸러진 소수의 후보 숙소에 대해서만 ST_Distance_Sphere 함수를 사용해 실제 거리를 계산하여 정확하게 반경 5km 이내에 위치한 숙소만 최종 결과를 반환하도록 재설계했습니다.
쿼리 최적화
위에 재설계한 내용을 바탕으로 숙소 검색 API의 쿼리를 재작성해봤습니다.
Bounding Box 생성 쿼리
SET @user_lat = 37.5665;
SET @user_lon = 126.9780;
SET @radius_km = 5; -- 5km 반경
-- 검색할 사각형 영역(Bounding Box)의 최소/최대 위도, 경도 계산
SET @lat_diff = @radius_km / 111.045;
SET @lon_diff = @radius_km / (111.045 * COS(RADIANS(@user_lat)));
SET @min_lat = @user_lat - @lat_diff;
SET @max_lat = @user_lat + @lat_diff;
SET @min_lon = @user_lon - @lon_diff;
SET @max_lon = @user_lon + @lon_diff;
-- 사각형 영역을 나타내는 POLYGON GEOMETRY 생성
SET @bounding_box = ST_GeomFromText(
CONCAT('POLYGON((',
CONCAT_WS(',',
CONCAT_WS(' ', @min_lat, @min_lon),
CONCAT_WS(' ', @min_lat, @max_lon),
CONCAT_WS(' ', @max_lat, @max_lon),
CONCAT_WS(' ', @max_lat, @min_lon),
CONCAT_WS(' ', @min_lat, @min_lon)
),
'))'),
4326
);
최적화한 첫 번째 쿼리
EXPLAIN ANALYZE
SELECT
a1_0.id,
a1_0.address_id,
a2_0.id AS address_id,
a2_0.base_address,
a2_0.country,
a2_0.detailed_address,
a2_0.location,
a1_0.bathroom_count,
a1_0.bed_count,
a1_0.bedroom_count,
a1_0.created_at,
a1_0.currency,
a1_0.description,
a1_0.max_guests,
a1_0.name,
a1_0.price_per_day,
a1_0.updated_at
FROM
accommodation a1_0
JOIN
address a2_0 ON a2_0.id = a1_0.address_id
WHERE
-- 1
MBRContains(@bounding_box, a2_0.location)
-- 2
AND a1_0.price_per_day >= 100000
AND a1_0.price_per_day <= 500000
AND a1_0.max_guests >= 1
-- 3
AND NOT EXISTS (
SELECT 1
FROM availability a3_0
WHERE a3_0.accommodation_id = a1_0.id
AND a3_0.date IN ('2025-08-28', '2025-08-30')
)
-- 4
AND ST_Distance_Sphere(
a2_0.location,
@user_location
) <= 5000
ORDER BY
a1_0.price_per_day
LIMIT 0, 30;
최적화한 두 번째 쿼리
SELECT
COUNT(a1_0.id)
FROM
accommodation a1_0
JOIN
address a4_0
ON a4_0.id = a1_0.address_id
WHERE
-- 1
MBRContains(@bounding_box, a4_0.location)
-- 2
AND a1_0.price_per_day >= 100000
AND a1_0.price_per_day <= 500000
AND a1_0.max_guests >= 1
-- 3
AND NOT EXISTS (
SELECT 1
FROM availability a3_0
WHERE a3_0.accommodation_id = a1_0.id
AND a3_0.date IN ('2025-08-28', '2025-08-30')
)
-- 4
AND ST_Distance_Sphere(
a4_0.location,
@user_location
) <= 5000;WHERE 절에 조건 순서에 따라도 성능차이가 크게 발생할 수 있기 때문에 순서도 함께 조정했습니다.
그래서 설정한 순서는 다음과 같습니다.
- 가장 먼저 공간 인덱스로 후보를 대폭 축소
- 인덱스를 탈 수 있는 간단한 조건으로 필터링
- 위 조건들을 통과한 소수의 후보에 대해서만 비싼 NOT EXISTS를 실행
- 마지막으로, 모든 조건을 통과한 최종 후보에 대해서만 정확한 거리 계산
이렇게 다시 작성한 쿼리를 EXPLAIN ANALYZE를 통해 성능을 다시 측정해 봤습니다.
첫 번째 쿼리 실행 결과
-> Limit: 30 row(s) (actual time=58.3..58.3 rows=30 loops=1)
-> Sort: a1_0.price_per_day, limit input to 30 row(s) per chunk (actual time=58.3..58.3 rows=30 loops=1)
-> Stream results (cost=465 rows=408) (actual time=9.16..56.7 rows=138 loops=1)
-> Nested loop antijoin (cost=465 rows=408) (actual time=9.15..56.3 rows=138 loops=1)
-> Nested loop inner join (cost=379 rows=44.8) (actual time=8.88..49.2 rows=138 loops=1)
-> Filter: (mbrcontains(<cache>((@bounding_box)),a2_0.location) and (st_distance_sphere(a2_0.location,<cache>((@user_location))) <= 5000)) (cost=208 rows=179) (actual time=8.01..22.3 rows=201 loops=1)
-> Index range scan on a2_0 using idx_location over (location unprintable_geometry_value) (cost=208 rows=179) (actual time=6.41..19 rows=256 loops=1)
-> Filter: ((a1_0.price_per_day >= 100000) and (a1_0.price_per_day <= 500000) and (a1_0.max_guests >= 1)) (cost=0.858 rows=0.25) (actual time=0.134..0.134 rows=0.687 loops=201)
-> Single-row index lookup on a1_0 using UK62xhvx41orw68v80u7iyq3y5i (address_id = a2_0.id) (cost=0.858 rows=1) (actual time=0.133..0.133 rows=1 loops=201)
-> Filter: (a3_0.`date` in ('2025-08-28','2025-08-30')) (cost=9.34 rows=9.11) (actual time=0.0513..0.0513 rows=0 loops=138)
-> Covering index lookup on a3_0 using UKchn2is0hq8qldeice3wbpyhg1 (accommodation_id = a1_0.id) (cost=9.34 rows=9.11) (actual time=0.0504..0.0509 rows=3.81 loops=138)
두 번째 쿼리 실행 결과
-> Aggregate: count(a1_0.id) (cost=559 rows=1) (actual time=15.4..15.4 rows=1 loops=1)
-> Nested loop antijoin (cost=465 rows=408) (actual time=0.684..15.2 rows=138 loops=1)
-> Nested loop inner join (cost=379 rows=44.8) (actual time=0.666..14 rows=138 loops=1)
-> Filter: (mbrcontains(<cache>((@bounding_box)),a4_0.location) and (st_distance_sphere(a4_0.location,<cache>((@user_location))) <= 5000)) (cost=208 rows=179) (actual time=0.493..10.4 rows=201 loops=1)
-> Index range scan on a4_0 using idx_location over (location unprintable_geometry_value) (cost=208 rows=179) (actual time=0.267..2.59 rows=256 loops=1)
-> Filter: ((a1_0.price_per_day >= 100000) and (a1_0.price_per_day <= 500000) and (a1_0.max_guests >= 1)) (cost=0.858 rows=0.25) (actual time=0.0177..0.0177 rows=0.687 loops=201)
-> Single-row index lookup on a1_0 using UK62xhvx41orw68v80u7iyq3y5i (address_id = a4_0.id) (cost=0.858 rows=1) (actual time=0.0173..0.0173 rows=1 loops=201)
-> Filter: (a3_0.`date` in ('2025-08-28','2025-08-30')) (cost=9.34 rows=9.11) (actual time=0.00836..0.00836 rows=0 loops=138)
-> Covering index lookup on a3_0 using UKchn2is0hq8qldeice3wbpyhg1 (accommodation_id = a1_0.id) (cost=9.34 rows=9.11) (actual time=0.00665..0.00778 rows=3.81 loops=138)
세 번째 쿼리 실행 결과
-> Nested loop inner join (cost=1.45 rows=1) (actual time=0.0356..0.0356 rows=0 loops=1)
-> Filter: (l1_0.accommodation_id in (4399,934817,784305,106569,583077,286932,983237,282482,251171,746635,60996,699832,456513,698740,579354,674807,615123,800972,352178,935329,87017,711005,325384,341966,522826,11786,492547,492383,348196,635737)) (cost=0.35 rows=1) (actual time=0.0352..0.0352 rows=0 loops=1)
-> Table scan on l1_0 (cost=0.35 rows=1) (actual time=0.0299..0.0338 rows=1 loops=1)
-> Filter: (l1_1.id = l1_0.label_id) (cost=1.1 rows=1) (never executed)
-> Single-row index lookup on l1_1 using PRIMARY (id = l1_0.label_id) (cost=1.1 rows=1) (never executed)
최적화 후 실행 속도는 다음과 같았습니다.
- 첫 번째 쿼리: 58.3ms
- 두 번째 쿼리: 15.4ms
- 세 번째 쿼리: 0.0356ms
총 세 개의 쿼리 실행 시간은 약 0.074초로 측정되었습니다.
EXPLAIN ANALYZE 결과를 통해 확인한 바에 따르면, 이전에는 발생하던 Table Scan이 사라지고, 대신 공간 인덱스를 활용하여 숙소 데이터를 효율적으로 조회할 수 있게 되었습니다.
이러한 쿼리 최적화를 통해 기존 4.2초에서 약 0.074초로, 약 57배 향상된 속도를 달성할 수 있었습니다.
최적화한 쿼리 적용과 테스트 (Feat. QueryDSL의 한계)
앞서 최적화한 쿼리를 실제 API에 적용해 봤습니다.
숙소 검색 API는 이전부터 QueryDSL을 사용하여 쿼리를 사용했기 때문에 QueryDSL로 코드를 수정했습니다.
@RequiredArgsConstructor
public class AccommodationRepositoryImpl implements AccommodationRepositoryCustom {
private final JPAQueryFactory queryFactory;
private final int RADIUS_METERS = 5000; // 5km radius
@Override
public Page<Accommodation> findFilteredAccommodations(Pageable pageable, FilterCondition filterCondition) {
QAccommodation accommodation = QAccommodation.accommodation;
QAvailability availability = QAvailability.availability;
double lon = filterCondition.longitude();
double lat = filterCondition.latitude();
Integer minPrice = filterCondition.minPrice();
Integer maxPrice = filterCondition.maxPrice();
Integer maxGuests = filterCondition.maxGuests();
List<LocalDate> requestedDates = filterCondition.requestedDates();
Point userLocation = GeoFactory.createPoint(lon, lat);
Polygon boundingBox = GeoFactory.createBoundingBox(lon, lat);
List<Accommodation> accommodations = queryFactory
.selectFrom(accommodation)
.join(accommodation.address).fetchJoin()
.where(
Expressions.numberTemplate(
Integer.class,
"MBRContains({0}, {1})",
Expressions.constant(boundingBox),
accommodation.address.location
).eq(1),
minPrice != null ? accommodation.pricePerDay.goe(minPrice) : null,
maxPrice != null ? accommodation.pricePerDay.loe(maxPrice) : null,
maxGuests != null ? accommodation.maxGuests.goe(maxGuests) : null,
JPAExpressions.selectOne()
.from(availability)
.where(
availability.accommodation.eq(accommodation),
availability.date.in(requestedDates)
)
.notExists(),
Expressions.booleanTemplate(
"ST_Distance_Sphere({0}, {1}) <= {2}",
accommodation.address.location,
Expressions.constant(userLocation),
RADIUS_METERS
)
)
.orderBy(accommodation.pricePerDay.asc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
Long total = queryFactory
.select(accommodation.count())
.from(accommodation)
.where(
Expressions.numberTemplate(
Integer.class,
"MBRContains({0}, {1})",
Expressions.constant(boundingBox),
accommodation.address.location
).eq(1),
minPrice != null ? accommodation.pricePerDay.goe(minPrice) : null,
maxPrice != null ? accommodation.pricePerDay.loe(maxPrice) : null,
maxGuests != null ? accommodation.maxGuests.goe(maxGuests) : null,
JPAExpressions.selectOne()
.from(availability)
.where(
availability.accommodation.eq(accommodation),
availability.date.in(requestedDates)
)
.notExists(),
Expressions.booleanTemplate(
"ST_Distance_Sphere({0}, {1}) <= {2}",
accommodation.address.location,
Expressions.constant(userLocation),
RADIUS_METERS
)
)
.fetchOne();
long safeTotal = total != null ? total : 0L;
return new PageImpl<>(accommodations, pageable, safeTotal);
}
}
다음과 같이 QueryDSL로 최적화 쿼리와 동일하게 코드를 수정한 뒤 숙소 검색 API를 호출하여 결과를 확인해 봤습니다.
더 느려진 응답속도?!
EXPLAIN ANALYZE 결과를 통해 확인한 결과처럼 0.1초도 걸리지 않을 정도의 빠른 응답 속도를 예상했지만, 확인해 본 결과 약 10초가 소요되는 예기치 못한 결과를 확인할 수 있었습니다.

처음에는 잘못 작성된 코드 때문에 응답이 느려진 것이라 생각하여 코드를 다시 확인하고, 로그에 찍히는 쿼리도 검토했습니다. 그러나 코드상에는 문제가 없었고, 로그에 남은 쿼리도 최적화된 쿼리와 동일했습니다. 그럼에도 불구하고 API 응답은 이전보다 두 배 이상 느려졌다는 것에 의아함이 들었습니다.
EXPLAIN ANALYZE에서는 쿼리 실행이 매우 빨랐지만 실제 API에 적용했을 때는 동일 쿼리 수행에 약 10초가 소요되는 현상이 발견되었습니다. 처음엔 직렬화나 네트워크 등 DB 외부 구간에서 지연이 발생한 것이 아닐까 의심했지만, DB 처리 시간과 서비스 로직 실행 시간을 각각 로깅해 비교해 보니 대부분의 시간이 DB 처리 구간에서 소요되고 있었습니다.
현재 숙소 검색 API는 DB 관련 코드 외에 특별한 변경이 없었으므로 서비스 로직 문제 가능성은 낮다고 판단했고, 결국 방금 작성한 QueryDSL 코드에 병목이 있을 가능성을 의심하게 되었습니다.
QueryDSL의 한계
다음 문제에 대해서 관련 책을 찾아보고 검색을 해본 결과 원인은 QueryDSL에서의 공간 함수 미지원으로 바인딩 시 많은 비용이 발생한다는 것을 알 수 있었습니다.
일반적인 쿼리의 경우, QueryDSL은 내부적으로 다음과 같은 과정을 거쳐 쿼리를 처리합니다. 예를 들어 아래와 같은 QueryDSL 코드가 실행된다고 가정해 보겠습니다.
List<Accommodation> result = queryFactory
.selectFrom(accommodation)
.where(accommodation.pricePerDay.goe(100000))
.fetch();

Java 애플리케이션 단에서는 accommodation.pricePerDay.goe(100000) 같은 조건을 통해 QueryDSL의 BooleanExpression 객체를 생성하고, 이를 QueryDSL 쿼리 빌더에 전달합니다.
QueryDSL은 전달받은 BooleanExpression을 분석하여 JPQL 문자열을 생성하고, JPQL 실행 시 필요한 파라미터 맵을 구성한 뒤 Hibernate에 전달합니다.
Hibernate는 전달받은 JPQL을 실제 SQL로 변환하고, 파라미터 타입을 매핑 및 검증한 후 JDBC로 전달합니다.
JDBC는 변환된 SQL을 기반으로 PreparedStatement를 생성하고, SQL과 파라미터를 DBMS에 전달하여 실제 쿼리를 실행합니다.
하지만, QueryDSL에서 미지원하는 공간 함수를 사용했을 때는 다음과 같은 과정을 걸쳐 쿼리를 처리하게 됩니다.
예를 들어, 다음과 같은 공간함수를 사용하는 QueryDSL 코드가 실행된다고 가정해 보겠습니다.
Polygon boundingBox = GeoFactory.createBoundingBox(lon, lat);
List<Accommodation> result = queryFactory
.selectFrom(accommodation)
.where(
Expressions.numberTemplate(
Integer.class,
"MBRContains({0}, {1})",
Expressions.constant(boundingBox),
accommodation.address.location
).eq(1)
)
.fetch();
Java 애플리케이션 단에서는 생성된 Polygon 객체와 NumberTemplate 객체를 QueryDSL 쿼리 빌더에 전달합니다.
하지만 QueryDSL은 공간 함수를 기본적으로 지원하지 않기 때문에, NumberTemplate에 포함된 "MBRContains({0}, {1})" 표현식을 인식하지 못하고 단순한 문자열로 치환합니다.
이렇게 치환된 문자열을 포함하여 JPQL 문자열을 생성하고, Polygon 객체를 그대로 파라미터 맵에 담아 Hibernate로 전달합니다.
Hibernate는 전달받은 JPQL 중 "MBRContains"를 표준 JPQL 함수로 인식하지 못하기 때문에 Native SQL로 처리합니다.
이후 JPQL 문자열을 실제 SQL로 변환하면서, 파라미터로 전달된 공간 데이터 타입(Polygon)을 감지하여 Hibernate Spatial 모듈을 호출합니다.
Hibernate Spatial은 Polygon 객체를 WKB(Well-Known Binary) 형식으로 직렬화한 뒤, 이를 JDBC로 전달합니다.
JDBC는 전달받은 WKB 데이터를 PreparedStatement에 바이너리 형태로 바인딩하여 DBMS에 전송합니다.
이때, WKB 바이너리 데이터는 일반적인 primitive 타입에 비해 데이터 크기가 크기 때문에 네트워크 오버헤드가 발생하게 됩니다.
또한 DBMS는 전달받은 WKB 데이터를 GEOMETRY 타입으로 역직렬화해야 해야 하며, 이 과정에서 매번 다른 바이너리로 인식되어 캐싱되지 않고, 각 row 비교 시마다 GEOMETRY 변환 연산이 반복되어 추가적인 비용이 발생합니다.
그 공간 함수(MBRContains)를 QueryDSL이 지원하지 않아 문자열로 치환되며, Hibernate → JDBC → DBMS로 전달되는 과정에서 WKB 직렬화 및 역직렬화가 반복되어 네트워크 및 변환 비용이 크게 발생해서 앞서 최적화를 했음에도 API 속도가 느렸던 것이었습니다.
Native SQL 사용하여 문제 해결
공간 함수와 공간 데이터 타입을 다룰 때는 QueryDSL의 성능 한계가 있기 때문에, QueryDSL 아닌 Native SQL을 통해 직접 SQL을 작성해 전달하기로 했습니다.
QueryDSL과 다르게 Native SQL은 까다로운 바인딩 절차가 없이 SQL 문자열을 전달하기 때문에 용량이 작아 크게 네트워크 오버헤드가 없기 때문에 정말 빠른 속도로 처리가 가능합니다.
그러기 때문에 지금처럼 QueryDSL에서 지원하지 않는 공간 함수를 사용할 때 불필요한 바인딩 비용과 네트워크 오버헤드 없이 쿼리를 처리할 수 있습니다.
다음과 같이 Native SQL을 통해 숙소 검색 API 쿼리 코드를 다시 작성해 보았습니다.
@RequiredArgsConstructor
public class AccommodationRepositoryImpl implements AccommodationRepositoryCustom {
private final EntityManager entityManager;
private final int RADIUS_METERS = 5000;
@Override
public Page<Accommodation> findFilteredAccommodations(Pageable pageable, FilterCondition filterCondition) {
double lon = filterCondition.longitude();
double lat = filterCondition.latitude();
// Bounding Box 계산
double latDiff = RADIUS_METERS / 111045.0;
double lonDiff = RADIUS_METERS / (111045.0 * Math.cos(Math.toRadians(lat)));
double minLat = lat - latDiff;
double maxLat = lat + latDiff;
double minLon = lon - lonDiff;
double maxLon = lon + lonDiff;
String boundingBoxWKT = String.format(
"POLYGON((%f %f, %f %f, %f %f, %f %f, %f %f))",
minLat, minLon,
minLat, maxLon,
maxLat, maxLon,
maxLat, minLon,
minLat, minLon
);
String userLocationWKT = String.format("POINT(%f %f)", lon, lat);
// 데이터 조회 쿼리
String dataSql = """
SELECT a.*
FROM accommodation a
JOIN address ad ON ad.id = a.address_id
WHERE MBRContains(ST_GeomFromText(:boundingBox, 4326), ad.location)
AND a.price_per_day >= :minPrice
AND a.price_per_day <= :maxPrice
AND a.max_guests >= :maxGuests
AND NOT EXISTS (
SELECT 1 FROM availability av
WHERE av.accommodation_id = a.id
AND av.date IN :dates
)
AND ST_Distance_Sphere(ad.location, ST_SRID(ST_GeomFromText(:userLocation), 4326)) <= :radius
ORDER BY a.price_per_day
LIMIT :limit OFFSET :offset
""";
Query dataQuery = entityManager.createNativeQuery(dataSql, Accommodation.class)
.setParameter("boundingBox", boundingBoxWKT)
.setParameter("userLocation", userLocationWKT)
.setParameter("minPrice", filterCondition.minPrice())
.setParameter("maxPrice", filterCondition.maxPrice())
.setParameter("maxGuests", filterCondition.maxGuests())
.setParameter("dates", filterCondition.requestedDates())
.setParameter("radius", RADIUS_METERS)
.setParameter("limit", pageable.getPageSize())
.setParameter("offset", pageable.getOffset());
// 데이터 카운트 쿼리
@SuppressWarnings("unchecked")
List<Accommodation> accommodations = dataQuery.getResultList();
String countSql = """
SELECT COUNT(a.id)
FROM accommodation a
JOIN address ad ON ad.id = a.address_id
WHERE MBRContains(ST_GeomFromText(:boundingBox, 4326), ad.location)
AND a.price_per_day >= :minPrice
AND a.price_per_day <= :maxPrice
AND a.max_guests >= :maxGuests
AND NOT EXISTS (
SELECT 1 FROM availability av
WHERE av.accommodation_id = a.id
AND av.date IN :dates
)
AND ST_Distance_Sphere(ad.location, ST_SRID(ST_GeomFromText(:userLocation), 4326)) <= :radius
""";
Query countQuery = entityManager.createNativeQuery(countSql)
.setParameter("boundingBox", boundingBoxWKT)
.setParameter("userLocation", userLocationWKT)
.setParameter("minPrice", filterCondition.minPrice())
.setParameter("maxPrice", filterCondition.maxPrice())
.setParameter("maxGuests", filterCondition.maxGuests())
.setParameter("dates", filterCondition.requestedDates())
.setParameter("radius", RADIUS_METERS);
long total = ((Number)countQuery.getSingleResult()).longValue();
return new PageImpl<>(accommodations, pageable, total);
}
}
코드를 수정했으니, 다시 숙소 검색 API를 호출해 정상적으로 성능이 개선되었는지 확인해 봤습니다.

다음과 같이 API 응답 속도 10초에서 160배가량 빨라진 0.062초의 응답 속도가 결과를 나온 것을 확인할 수 있었습니다.
이렇게 쿼리 최적화를 통해 숙소 검색 API의 응답속도를 빠르게 개선하였습니다!
마치며
이번 쿼리 최적화를 통해 인덱스와 공간 인덱스를 깊이 배울 수 있었습니다. 단순히 인덱스를 '추가하는 것'을 넘어, 그 구조와 동작 원리를 이해하고, 어떤 사항을 고려해야 최적으로 활용할 수 있는지 고민해 보며 심도 있게 학습해 볼 수 있었습니다. 특히, 쿼리 최적화 과정을 직접 경험하면서 빠른 속도의 서비스를 사용자에게 제공할 수 있는 실질적인 역량을 키울 수 있었습니다.
또한, QueryDSL을 사용하면서 기술의 한계와 장단점에 대한 통찰을 얻게 되었습니다. QueryDSL은 개발 생산성을 높여주지만, 복잡한 쿼리나 최적화가 필요한 특정 상황에서는 Native SQL에 비해 성능적 병목을 일으킬 수 있음을 확인했습니다.
이 경험은 저에게 "하나의 기술에 맹목적으로 의존하기보다는, 각 기술의 장단점을 명확히 파악하고, 서비스의 요구사항과 성능 목표에 맞춰 적절한 도구를 선택하여 사용해야 한다"는 중요한 교훈을 남겼습니다. 특정 기술에 대한 의존성을 줄이고 상황에 맞는 유연한 아키텍처를 설계하는 능력이 엔지니어에게 얼마나 중요한지 깨닫게 된 소중한 시간이었습니다.
오늘 경험들을 바탕으로 기술에 대한 깊은 이해를 지속적으로 확장하며, 서비스에 적합한 기술을 활용해 최고의 사용자 경험을 제공하는 개발자로 성장하고 싶습니다!
참고 자료
Real MySQL 8.0 (1권) | 백은빈
eBook Real MySQL 8.0 (1권) | MySQL 서버를 활용하는 프로젝트에 꼭 필요한 경험과 지식을 담았습니다! 《Real MySQL 8.0》은 《Real MySQL》을 정제해서 꼭 필요한 내용으로 압축하고, MySQL 8.0의 GTID와 InnoDB 클
ebook-product.kyobobook.co.kr
MySQL :: MySQL 8.0 Reference Manual :: 10.8 Understanding the Query Execution Plan
10.8 Understanding the Query Execution Plan Depending on the details of your tables, columns, indexes, and the conditions in your WHERE clause, the MySQL optimizer considers many techniques to efficiently perform the lookups involved in an SQL query. A qu
dev.mysql.com